joinpoint에 Advice가 삽입되는데 Advice에는 5가지 시점(@After, @AfterReturning, @AfterThrowing, @Around, @Before )이 존재합니다. 그 중 Around에는 메소드 호출 자체를 가로채서 비즈니스 메소드 실행 전,후 모두에 처리할 로직을 삽입 할 수 있습니다.
저는 LoginCheck를 할 시 메소드 호출를 가로챌 수 있도록 만들었고, 세션 값과 isAdmin 값을 설정하였습니다.
@log4j2
logging이란 어떤 이벤트가 발생했을 때 로그가 남는 것을 의미합니다. 이 어노테이션을 사용하면 로그인기록이 남아 로그인이 되었는지를 확인할 수 있습니다.
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface LoginCheck {
public static enum Role{
USER,ADMIN
}
Role type();
}
public class CUserNotFoundException extends RuntimeException {
public CUserNotFoundException(String msg, Throwable t) {
super(msg, t);
}
public CUserNotFoundException(String msg) {
super(msg);
}
public CUserNotFoundException() {
super();
}
}
@RestControllerAdvice와 @ExceptionHandler를 설정하면 공통 코드로 분리하여 예외처리를 해버릴 수 있습니다.
만약 특정 Controller만 예외 처리를 하고 싶으시면 하위 Controller를 설정해서 예외처리가 적용될 것 입니다. 저 같은 경우에는 전체를 예외 처리하되, 만들 당시에 에러 로그를 읽어야 하는데 예외 처리로 넘어가져버려서 일단 주석 처리를 한 후 에러 부분을 수정한 후에 다시 예외 처리를 하는 식으로 해결을 하였는데 각자 편하신 대로 하셨으면 좋겠습니다.
@ExceptionHandler(Exception.class)는 예외 처리의 최상위를 담당하여 어떤 예외에 걸리지 않으면 이 예외를 통과
@ExceptionHandler(CUserNotFoundException.class)는 커스텀 예외 처리로 유저가 발견되지 않을 시 이 예외를 통과
messageSource는 code와 args와 LocaleContextHoler.getLocale()을 읽어 현재에 맞는 메세지를 가져옵니다.
CUserNotFoundException이라는 Custom Exception 만들어서 유저가 조회되지 않을 때 예외 상황을 알려줍니다.
실제 UserController에서 Login을 하였을 때 유저의 정보가 null 값일 시 CUserNotFoundException이 실행되도록 하였습니다.
API 호출을 하였을 때 정상적으로 호출되는 것을 볼수 있습니다.
이번에 Custom 예외 처리를 하면서 이해가 안가는 부분들이 있었습니다. 공식 문서를 통해 @Controller와 @ControllerAdvice 클래스들은 Controller 메소드로부터 발생한 exception들을 처리하기 위해 @ExceptionHandler 메소드를 갖는다라고 하는데 Handler가 정확히 어떤 의미인지에 대해 궁금해져서 검색을 해보니 Controller에 @RequestMapping 어노테이션이 붙은 메서드를 의미로 사용한다라는 점을 알게 되어 흥미로웠습니다.
Controller는 Vew와 Model 사이의 중개자 역할을 한다고 보면 됩니다. View에서 받은 요청을 처리하며, Model에게 어떻게 요청을 처리할지 알려주는 역할을 합니다.
MVC 패턴을 사용하는 이유는 사용자에게 보여지는 UI 로직과 비즈니스 로직이 독립적이기 때문에 서로 상관하지 않고 원하는 부분만 따로 처리할 수 있으며, 유지 보수에 용이합니다.
MVC 패턴에 따라 Book,User,Help,Content Controller단을 만들었으며, Idol-Ticketing 서버 프로젝트를 하면서 제일 첫번째로 한 것은 계정 정보를 관리 할 수 있는 기능을 만드는 것이였습니다.
userController
@RestController
@RequestMapping(value = "/users")
public class UserController {
@Autowired
UserMapper userMapper;
private final UserService userService;
public UserController(UserService userService) {
this.userService = userService;
}
@PutMapping(value = "/login")//로그인
public ResponseEntity<?> login(@RequestBody UserDTO userDTO, HttpSession session) {
UserDTO userInfo = userService.login(userDTO);
if (userInfo.isAdmin() == false) {
SessionUtil.setLoginUserId(session, userInfo.getUserId());
return new ResponseEntity<>(UserResponseDTO.builder()
.userId(userInfo.getUserId())
.name(userInfo.getName())
.code(201)
.message("일반 유저 로그인 성공").build(), HttpStatus.OK);
} else if (userInfo.isAdmin()) {
SessionUtil.setLoginAdminId(session, userInfo.getUserId());
return new ResponseEntity<>(UserResponseDTO.builder()
.userId(userInfo.getUserId())
.name(userInfo.getName())
.code(202)
.message("관리자 로그인 성공").build(), HttpStatus.OK);
} else {
return new ResponseEntity<>(UserResponseDTO.builder()
.code(401)
.message("로그인 실패").build(), HttpStatus.NOT_FOUND);
}
}
REST API
UserController를 만들때는 REST API URI 규칙을 지키며 회원가입, 로그인, 회원 수정, 로그아웃, 탈퇴 기능을 구성하였습니다.
REST는 Representational State Transfer의 약자로 클라이언트와 서버간에 데이터를 주고 받을 때 방식에 대한 아키텍처 스타일입니다.
REST API를 사용하는 이유는 웹의 장점(네트워크 연결만 되면 어디서든 실행이 가능하다.)을 활용할 수 있는 아키텍처로 만든 것이 REST이며, 가장 큰 특징은 각 요청이 어떤 동작이나 정보를 위한 것인지를 그 요청의 모습 자체로 추론이 가능하기 때문입니다.
REST API URI 규칙
소문자를 사용한다.
언더바 대신 하이픈을 사용한다.
URI의 마지막에는 슬래시를 포함하지 않는다.
계층관계를 나타낼 때는 슬래시 구분자를 사용해야 한다.
파일 확장자는 URI에 포함시키지 않는다.
전달하고자 하는 자원의 명사를 사용하되, 컨트롤 자원을 의미하는 경우 예외적으로 동사를 허용한다.
URI에 작성되는 영어를 복수형으로 작성한다.
userDTO
@Data
@Builder
public class UserDTO {
private String userId; //아이디
private String name; //이름
private String password; //비밀번호
public UserDTO(){
}
public UserDTO(String userId,String name,String password){
this.userId = userId;
this.name = name;
this.password = password;
}
}
실제 DB에 들어갈 값들을 작성하여 userDTO로 구성하였습니다.
DTO를 사용하면 클라이언트가 요청한 데이터를 담아 전달하는 역할을 합니다.
DB Connection은 Java와 DB를 연결 객체로 연결될 때마다 객체를 만들면 db의 정보를 넘겨야하기 때문에 소요시간이 오래걸립니다. 그렇기 때문에 DB Connection Pool 값을 늘려 미리 DB Connection 객체를 많이 만들어 놓습니다.
userService
@Service
public class UserServiceImpl implements UserService {
@Autowired
UserMapper userMapper;
@Override
public UserDTO login(UserDTO userDTO) {
return userMapper.findByIdAndPassword(userDTO);
}
}
@Service 을 통해 스프링 빈(Spring bean)이 자동으로 생성됩니다.
이는 스프링 특징인 제어의 역전(IoC)인데 객체의 생성 및 제어권을 사용자가 아닌 스프링이 맡는 것입니다.
userMappper.xml
<select id="findByIdAndPassword" resultType="dto.UserDTO">
SELECT userId,name,password,email,phone,address,isAdmin
FROM user
WHERE password = #{password}
AND userId = #{userId}
</select>
userMapper.java
@Mapper
public interface UserMapper {
UserDTO findByIdAndPassword (UserDTO userDTO);//로그인
}
Mybatis를 사용하여 mapper 코드를 xml으로 작성 후 userMapper 인터페이스를 만들어 @Mapper를 설정해 주었습니다. 이렇게 하면 mapper 코드들을 한번에 관리할 수 있다는 장점이 있습니다.
postman API 호출
post, 회원가입 , put, 로그인, patch, 회원 수정
put,로그아웃, delete, 회원탈퇴
API 호출까지 성공적으로 되는 것으로 파악되었으며, 이후 User Controller 뿐만 아니라, help,content,book Controller도 해결하였습니다.
Controller를 다루는 것이 처음은 아니였지만 REST API로 작업하는 것은 처음이였기 때문에 주소창에 값을 넘긴다는 것은 알지만 어떻게 넘겨야하는 것인지에 대해 명확히 개념이 잘 안서던 REST API에 대해 Patch는 리소스의 일부분의 값만 수정할 때 사용하고, Put은 리소스의 전체 값을 수정할 때 사용하며 get은@RequestBody을 쓰면 안되고 @RequestParam을 써야 한다고 정리할 수 있는 좋은 경험이 되었습니다.
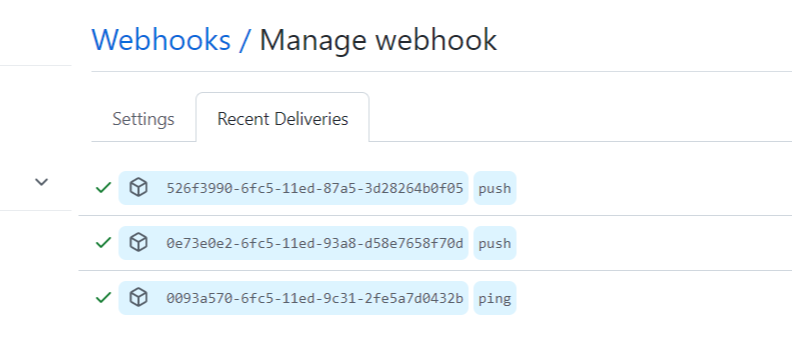
로컬에서 webhook에 접속하기 위해서는 ngrok 프로그램을 다운받아 주소를 받아야합니다.
ngrok http 젠킨스포트
Forwarding에 있는 주소를 복붙하셔서 webhook URL에 적으면 됩니다.
다시 git에 가서 push를 해보았을 때 정상적으로 push가 된 것을 볼 수 있습니다.
이번 젠킨스 CI/CD를 하면서 CI에 비해 CD에 대한 이해가 부족했던 것에 깨달았습니다. 지속적 배포라는 것이 자동화라는 것을 단순히 책으로만 외우다가 직접 git으로 push를 했을 때 젠킨스에서 빌드가 된다는 것을 보았을 때 이렇게 자동화가 이루어 지는 것이라면 너무 많은 빌드가 이루어지는 것보단 적은 빌드로 완성도 높은 프로그램을 만드는 것이 좋을 것이라 생각되었습니다.
시나리오 : 고척돔 기준 6만명이 접속해 1분안에 매진된다는 상황, 초당 1000tps를 목표로 성능테스트 진행 목표 : Min과 Max의 격차를 최소화 할 것, RPS : 1000.
테스트 1
가장 먼저 테스트했던 시나리오 결과입니다. min은 0.001초, max는 10.528로 격차가 크며, RPS는 191으로 적습니다.
- 원인 및 해결방안
B-tree 구조에서 삽입을 할 시 데이터를 조회 후 노드를 추가하고 자식 노드가 부모 노드보다 더 많다면 상향식으로 적절한 위치를 찾아가기 때문에 시간복잡도가 증가합니다. 더불어 현재 만들어진 Mysql에서 PK가 2개였기 때문에 index 값을 삭제할 시 RPS 값이 증가한다는 것을 확인하고 primary key 중에서 userId를 삭제를 했습니다.
*여기서 헷갈리는 부분이 PK가 두개라는 부분이 무결성의 원칙을 어기는 것이냐는 것이였습니다. 하지만 결론적으로 두 칼럼을 합쳤을 때 중복이 아니면 무결성의 원칙을 지키는 것이라는 것을 알게 되었습니다.
Ex) [A=1,B=1],[A=1,B=2]는 중복된 것이 아니다.
테스트 2
RPS가 거의 3배 값인 351로 증가한 것을 볼 수 있습니다. 하지만 min 값은 max 값은 오히려 11.611초로 증가했습니다.
마지막으로 해결해야하는 부분은 시간적 요소였습니다. 자바 프로그램에 DBMS로 커넥션을 생성하려면(생성할 때마다 db정보(db host, port, connection-poolsize, id, password, db name, encoinding)를 만듦) 시간이 많이 소요됩니다. 그러므로 미리 db 커넥션을 많이 만들어놓으므로 그 시간을 단축할 수 있도록 만드는 것입니다.
application.properties에서 connection-pool 값을 10에서 20으로 변경하였습니다.
spring.datasource.maximum-pool-size=20
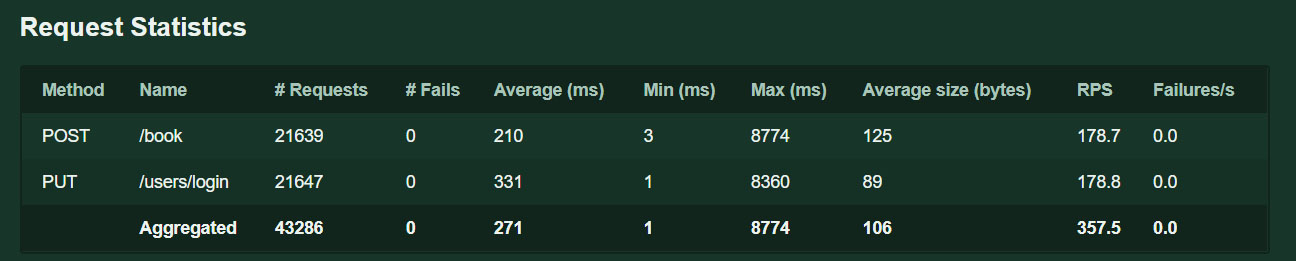
테스트 3
최종적으로 min 값은 0.001초 max 값은 8.774초 RPS는 357로 증가한 것을 볼 수 있습니다.
마무리로 RPS를 증가시키기 위해서 scale-out을 이용하여 다른 서버를 3개 정도 증설하면 기존 원했던 RPS 1000에 도달 할 수 있습니다.
locust을 이용해서 실제처럼 RPS 값을 볼 수 있다는 점이 재밌었던 기억이 납니다. 하지만 제 컴퓨터의 사양에 따라 달라졌던 값이였기 때문에 이것을 토대로 이렇구나를 참조하는 것이지 백프로 믿고 나아가기에는 문제가 있습니다.
또한 locust말고도 많은 성능 테스트가 있기 때문에 좀 더 다양한 경험을 쌓는 게 중요하지 않을 까 싶습니다.